|
|
4 years ago | |
|---|---|---|
| R | 4 years ago | |
| inst | 4 years ago | |
| java/htmlunit | 4 years ago | |
| man | 4 years ago | |
| tests | 4 years ago | |
| .Rbuildignore | 5 years ago | |
| .codecov.yml | 5 years ago | |
| .gitignore | 5 years ago | |
| .travis.yml | 5 years ago | |
| CODE_OF_CONDUCT.md | 5 years ago | |
| DESCRIPTION | 4 years ago | |
| LICENSE | 5 years ago | |
| NAMESPACE | 5 years ago | |
| NEWS.md | 4 years ago | |
| README.Rmd | 5 years ago | |
| README.md | 4 years ago | |
| htmlunit.Rproj | 5 years ago | |
README.md

![]()
![]()

![]()
![]()
![]()
htmlunit
Tools to Scrape Dynamic Web Content via the ‘HtmlUnit’ Java Library
Description
‘HtmlUnit’ (https://htmlunit.sourceforge.net/) is a “‘GUI’-Less browser for ‘Java’ programs”. It models ‘HTML’ documents and provides an ‘API’ that allows one to invoke pages, fill out forms, click links and more just like one does in a “normal” browser. The library has fairly good and constantly improving ‘JavaScript’ support and is able to work even with quite complex ‘AJAX’ libraries, simulating ‘Chrome’, ‘Firefox’ or ‘Internet Explorer’ depending on the configuration used. It is typically used for testing purposes or to retrieve information from web sites. Tools are provided to work with this library at a higher level than provided by the exposed ‘Java’ libraries in the ‘htmlunitjars’ package.
What’s Inside The Tin
The following functions are implemented:
DSL
-
web_client/webclient: Create a new HtmlUnit WebClient instance -
wc_go: Visit a URL -
wc_html_nodes: Select nodes from web client active page html content -
wc_html_text: Extract attributes, text and tag name from webclient page html content -
wc_html_attr: Extract attributes, text and tag name from webclient page html content -
wc_html_name: Extract attributes, text and tag name from webclient page html content -
wc_headers: Return response headers of the last web request for current page -
wc_browser_info: Retreive information about the browser used to create the ‘webclient’ -
wc_content_length: Return content length of the last web request for current page -
wc_content_type: Return content type of web request for current page -
wc_render: Retrieve current page contents -
wc_css: Enable/Disable CSS support -
wc_dnt: Enable/Disable Do-Not-Track -
wc_geo: Enable/Disable Geolocation -
wc_img_dl: Enable/Disable Image Downloading -
wc_load_time: Return load time of the last web request for current page -
wc_resize: Resize the virtual browser window -
wc_status: Return status code of web request for current page -
wc_timeout: Change default request timeout -
wc_title: Return page title for current page -
wc_url: Return load time of the last web request for current page -
wc_use_insecure_ssl: Enable/Disable Ignoring SSL Validation Issues -
wc_wait: Block HtlUnit final rendering blocks until all background JavaScript tasks have finished executing
Just the Content (pls)
hu_read_html: Read HTML from a URL with Browser Emulation & in a JavaScript Context
Content++
wc_inspect: Perform a “Developer Tools”-like Network Inspection of a URL
Installation
install.packages("htmlunit", repos = c("https://cinc.rud.is", "https://cloud.r-project.org/"))
# or
remotes::install_git("https://git.rud.is/hrbrmstr/htmlunit.git")
# or
remotes::install_git("https://git.sr.ht/~hrbrmstr/htmlunit")
# or
remotes::install_gitlab("hrbrmstr/htmlunit")
# or
remotes::install_bitbucket("hrbrmstr/htmlunit")
# or
remotes::install_github("hrbrmstr/htmlunit")
NOTE: To use the ‘remotes’ install options you will need to have the {remotes} package installed.
Usage
library(htmlunit)
library(tidyverse) # for some data ops; not req'd for pkg
# current verison
packageVersion("htmlunit")
## [1] '0.5.0'
Something xml2::read_html() cannot do, read the table from
https://hrbrmstr.github.io/htmlunitjars/index.html:
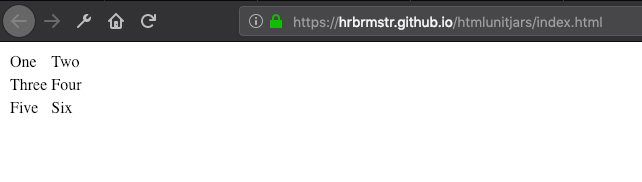
test_url <- "https://hrbrmstr.github.io/htmlunitjars/index.html"
pg <- xml2::read_html(test_url)
html_table(pg)
## list()
☹️
But, hu_read_html() can!
pg <- hu_read_html(test_url)
html_table(pg)
## [[1]]
## X1 X2
## 1 One Two
## 2 Three Four
## 3 Five Six
All without needing a separate Selenium or Splash server instance.
Content++
We can also get a HAR-like content + metadata dump:
xdf <- wc_inspect("https://rstudio.com")
colnames(xdf)
## [1] "method" "url" "status_code" "message" "content" "content_length"
## [7] "content_type" "load_time" "headers"
select(xdf, method, url, status_code, content_length, load_time)
## # A tibble: 36 x 5
## method url status_code content_length load_time
## <chr> <chr> <int> <dbl> <dbl>
## 1 GET https://rstudio.com/ 200 14621 495
## 2 GET https://metadata-static-files.sfo2.cdn.digitaloceanspaces.com/pixel/lp.js 200 3576 221
## 3 GET https://snap.licdn.com/li.lms-analytics/insight.min.js 200 1576 162
## 4 GET https://connect.facebook.net/en_US/fbevents.js 200 34269 138
## 5 GET https://connect.facebook.net/signals/config/151855192184380?v=2.9.23&r=s… 200 134841 66
## 6 GET https://munchkin.marketo.net/munchkin-beta.js 200 752 230
## 7 GET https://munchkin.marketo.net/159/munchkin.js 200 4810 27
## 8 GET https://x.clearbitjs.com/v1/pk_60c5aa2221e3c03eca10fb6876aa6df7/clearbit… 200 86568 483
## 9 GET https://cdn.segment.com/analytics.js/v1/gO0uTGfCkO4DQpfkRim9mBsjdKrehtnu… 200 62860 243
## 10 GET https://static.hotjar.com/c/hotjar-1446157.js?sv=6 200 1708 212
## # … with 26 more rows
group_by(xdf, content_type) %>%
summarise(
total_size = sum(content_length),
total_load_time = sum(load_time)/1000
)
## # A tibble: 7 x 3
## content_type total_size total_load_time
## <chr> <dbl> <dbl>
## 1 application/javascript 431338 2.58
## 2 application/json 4118 1.37
## 3 application/x-javascript 176248 0.623
## 4 image/gif 35 0.232
## 5 text/html 16640 1.36
## 6 text/javascript 254971 0.996
## 7 text/plain 28 0.189
DSL
wc <- web_client(emulate = "chrome")
wc %>% wc_browser_info()
## < Netscape / 5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36 / en-US >
wc <- web_client()
wc %>% wc_go("https://usa.gov/")
# if you want to use purrr::map_ functions the result of wc_html_nodes() needs to be passed to as.list()
wc %>%
wc_html_nodes("a") %>%
sapply(wc_html_text, trim = TRUE) %>%
head(10)
## [1] "Skip to main content" "" "Español"
## [4] "1-844-USA-GOV1" "All Topics and Services" "About the U.S."
## [7] "American Flag" "Branches of the U.S. Government" "Budget of the U.S. Government"
## [10] "Data and Statistics about the U.S."
wc %>%
wc_html_nodes(xpath=".//a") %>%
sapply(wc_html_text, trim = TRUE) %>%
head(10)
## [1] "Skip to main content" "" "Español"
## [4] "1-844-USA-GOV1" "All Topics and Services" "About the U.S."
## [7] "American Flag" "Branches of the U.S. Government" "Budget of the U.S. Government"
## [10] "Data and Statistics about the U.S."
wc %>%
wc_html_nodes(xpath=".//a") %>%
sapply(wc_html_attr, "href") %>%
head(10)
## [1] "#content" "/" "/espanol/" "/phone"
## [5] "/#tpcs" "#" "/flag" "/branches-of-government"
## [9] "/budget" "/statistics"
Handy function to get rendered plain text for text mining:
wc %>%
wc_render("text") %>%
substr(1, 300) %>%
cat()
## Official Guide to Government Information and Services | USAGov
## Skip to main content
## An official website of the United States government Here's how you know
##
##
## Main Navigation
## Search
## Search
## Search
## 1-844-USA-GOV1
## All Topics and Services
## Benefits, Grants, Loans
## Government Agencies and Elected Officials
htmlunit Metrics
| Lang | # Files | (%) | LoC | (%) | Blank lines | (%) | # Lines | (%) |
|---|---|---|---|---|---|---|---|---|
| R | 14 | 0.70 | 341 | 0.72 | 188 | 0.70 | 377 | 0.82 |
| Java | 3 | 0.15 | 52 | 0.11 | 23 | 0.09 | 3 | 0.01 |
| Rmd | 1 | 0.05 | 41 | 0.09 | 52 | 0.19 | 75 | 0.16 |
| Maven | 1 | 0.05 | 30 | 0.06 | 0 | 0.00 | 1 | 0.00 |
| make | 1 | 0.05 | 10 | 0.02 | 4 | 0.01 | 4 | 0.01 |
clock Package Metrics for htmlunit
Code of Conduct
Please note that this project is released with a Contributor Code of Conduct. By participating in this project you agree to abide by its terms.