---
title: "Introduction to splashr"
author: "Bob Rudis"
date: "`r Sys.Date()`"
output:
rmarkdown::html_vignette:
toc: true
vignette: >
%\VignetteIndexEntry{Introduction to splashr}
%\VignetteEngine{knitr::rmarkdown}
%\VignetteEncoding{UTF-8}
---
Capturing information/conent from internet resources can be a tricky endeavour. Along with the many legal + ethical issues there are an increasing numbner of sites that render content dynamically, either through `XMLHttpRequests` (XHR) or on-page JavaScript (JS) rendering of
in-page content. There are also many sites that make it difficult to fill-in form data programmatically.
There are ways to capture these types of resources in R. One way is via the [`RSelenium`](https://CRAN.R-project.org/package=RSelenium) ecosystem of packages. Another is with packages such as [`webshot`](https://CRAN.R-project.org/package=webshot). One can also write custom [`phantomjs`](http://phantomjs.org/) scripts and post-process the HTML output.
The `splashr` package provides tooling around another web-scraping ecosystem: [Splash](https://scrapinghub.com/splash). A Splash environment is fundamentally a headless web browser based on the QT WebKit library. Unlike the Selenium ecosystem, Splash is not based on the [WebDriver](https://www.w3.org/TR/webdriver/) protocol, but has a custom HTTP API that provides both similar and different idioms for accessing and maniuplating web content.
## Getting Started
Before you can use `splashr` you will need access to a Splash environment. You can either:
- [pay for instances](https://app.scrapinghub.com/account/signup/);
- [get a Splash server running locally by hand](https://github.com/scrapinghub/splash), or
- use Splash in a [Docker](https://www.docker.com/) container.
The package and this document are going to steer you into using Docker containers. Docker is free for macOS, Windows and Linux systems, plus most major cloud computing providers have support for Docker containers. If you don't have Docker installed, then your first step should be to get Docker going and [verifying your setup](https://docs.docker.com/get-started/).
Once you have Docker working, you can follow the [Splash installation guidance](https://splash.readthedocs.io/en/stable/install.html) to manually obtain, start and stop Splash docker containers. _There must be a running, accessible Splash instance for `splashr` to work_.
If you're comfortable trying to get a working Python environment working on your system, you can also use the Splash Docker helper functions that come with this package:
- `install_splash()` will perform the same operation as `docker pull ...`
- `start_splash()` will perform the same operation as `docker run ...`, and
- `stop_splash()` will stop and remove the conainter object returned by `start_splash()`
Follow the vignettes in the [`docker`](https://CRAN.R-project.org/package=docker) package to get the `docker` package up and running.
The remainder of this document assumes that you have a Splash instance up and running on your localhost.
## Scraping Bascis --- `render_` functions
Splash (and, hence, `splashr`) has a feature-rich API that ranges from quick-and-easy to complex-detailed-and-powerful. We'll start with some easy basics. First make sure Splash is running:
```
library(splashr)
splash_active()
## Status of splash instance on [http://localhost:8050]: ok. Max RSS: 74.42578 Mb
##
## [1] TRUE
```
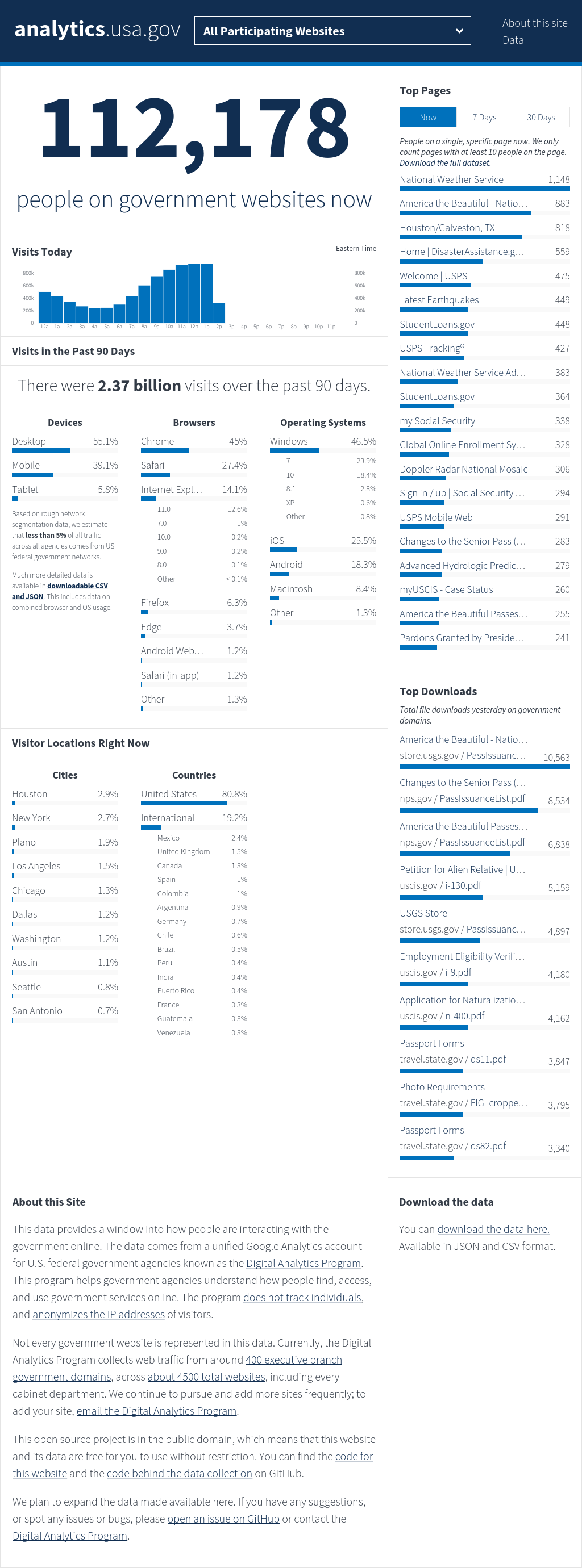
THe first action we'll perform may surprise you. We're going to take a screenshot of the site. Why that site? First, the Terms of Service allow for scraping. Second, it has a great deal of dynamic content. And, third, we can validate our scraping findings with a direct data download (which will be an exercise left to the reader).
Enough words. Let's see what this site looks like!
```
library(magick)
render_png(url = "https://analytics.usa.gov/", wait = 5)
## format width height colorspace filesize
## 1 PNG 1024 2761 sRGB 531597
```
Let's decompose what we just did:
1. We called `render_png()` function. The job of this function is to --- by default -- take a "screenshot" of the fully rendered page content at a specified URL.
1. We passed in the `url = ` parameter. The default first parameter is a `splashr` object created by the `splash()`. However, since it's highly likely most folks will be running a Splash server locally with the default configuration, most `splashr` functions will use an inherent, "`splash_local`" object if you're willing to use named parameters for all other parameter values.
1. We passed in a `wait = ` parameter, asking the Splash server to wait for a few seconds to give the content time to render. This is an important consideration which we'll go into later in this document.
1. `splashr` passed on our command to the running Splash instance and the Splash server sent back a PNG file which the `splashr` package read in with the help of the `magick` package. If you're operating in RStudio you'll see the above image in the viewer. Alternatively, you can do:
```
image_browse(render_png(url = "https://analytics.usa.gov/", wait = 5))
```
to see the image if you're in another R environment. NOTE: web page screenshots can be captured in PNG or JPEG format by choosing the appropriate `render_` function.
Now that we've validated that we're getting the content we want, we can do something a bit more useful, like retrieve the HTML content of the page:
```
pg <- render_html(url = "https://analytics.usa.gov/")
pg
## {xml_document}
##
## [1] \n\n\n
 Let's decompose what we just did:
1. We called `render_png()` function. The job of this function is to --- by default -- take a "screenshot" of the fully rendered page content at a specified URL.
1. We passed in the `url = ` parameter. The default first parameter is a `splashr` object created by the `splash()`. However, since it's highly likely most folks will be running a Splash server locally with the default configuration, most `splashr` functions will use an inherent, "`splash_local`" object if you're willing to use named parameters for all other parameter values.
1. We passed in a `wait = ` parameter, asking the Splash server to wait for a few seconds to give the content time to render. This is an important consideration which we'll go into later in this document.
1. `splashr` passed on our command to the running Splash instance and the Splash server sent back a PNG file which the `splashr` package read in with the help of the `magick` package. If you're operating in RStudio you'll see the above image in the viewer. Alternatively, you can do:
```
image_browse(render_png(url = "https://analytics.usa.gov/", wait = 5))
```
to see the image if you're in another R environment. NOTE: web page screenshots can be captured in PNG or JPEG format by choosing the appropriate `render_` function.
Now that we've validated that we're getting the content we want, we can do something a bit more useful, like retrieve the HTML content of the page:
```
pg <- render_html(url = "https://analytics.usa.gov/")
pg
## {xml_document}
##
## [1] \n\n\n
Let's decompose what we just did:
1. We called `render_png()` function. The job of this function is to --- by default -- take a "screenshot" of the fully rendered page content at a specified URL.
1. We passed in the `url = ` parameter. The default first parameter is a `splashr` object created by the `splash()`. However, since it's highly likely most folks will be running a Splash server locally with the default configuration, most `splashr` functions will use an inherent, "`splash_local`" object if you're willing to use named parameters for all other parameter values.
1. We passed in a `wait = ` parameter, asking the Splash server to wait for a few seconds to give the content time to render. This is an important consideration which we'll go into later in this document.
1. `splashr` passed on our command to the running Splash instance and the Splash server sent back a PNG file which the `splashr` package read in with the help of the `magick` package. If you're operating in RStudio you'll see the above image in the viewer. Alternatively, you can do:
```
image_browse(render_png(url = "https://analytics.usa.gov/", wait = 5))
```
to see the image if you're in another R environment. NOTE: web page screenshots can be captured in PNG or JPEG format by choosing the appropriate `render_` function.
Now that we've validated that we're getting the content we want, we can do something a bit more useful, like retrieve the HTML content of the page:
```
pg <- render_html(url = "https://analytics.usa.gov/")
pg
## {xml_document}
##
## [1] \n\n\n