|
|
7 years ago | |
|---|---|---|
| R | 7 years ago | |
| README_files/figure-markdown_github | 7 years ago | |
| img | 7 years ago | |
| man | 7 years ago | |
| tests | 7 years ago | |
| .Rbuildignore | 7 years ago | |
| .gitignore | 7 years ago | |
| .travis.yml | 7 years ago | |
| DESCRIPTION | 7 years ago | |
| NAMESPACE | 7 years ago | |
| NEWS.md | 7 years ago | |
| README.Rmd | 7 years ago | |
| README.md | 7 years ago | |
| splashr.Rproj | 7 years ago | |
README.md
splashr : Tools to Work with the 'Splash' JavaScript Rendering Service
TL;DR: This package works with Splash rendering servers which are really just a REST API & lua scripting interface to a QT browser. It's an alternative to the Selenium ecosystem which was really engineerdfor application testing & validation.
Sometimes, all you need is a page scrape after javascript has been allowed to roam wild and free over your meticulously craefted HTML tags. So, this package does not do everything Selenium can, but if you're just trying to get a page back that needs javascript rendering, this is a nice alternative.
It's also an alternative to phantomjs (which you can use in R within or without a Selenium context as it's it's own webdriver) and it may be useful to comapre renderings between this package & phantomjs.
You can also get it running with two commands:
sudo docker pull scrapinghub/splash
sudo docker run -p 5023:5023 -p 8050:8050 -p 8051:8051 scrapinghub/splash
(Do whatever you Windows ppl do with Docker on your systems to make ^^ work.)
You can run Selenium in Docker, so this is not unique to Splash. But, Docker context makes it so that you don't have to run or maintain icky Python stuff directly on your system. Leave it in the abandoned warehouse district where it belongs.
All you need for this package to work is a running Splash instance. You provide the host/port for it and it's scrape-tastic fun from there!
About Splash
'Splash' https://github.com/scrapinghub/splash is a javascript rendering service. It’s a lightweight web browser with an 'HTTP' API, implemented in Python using 'Twisted'and 'QT' and provides some of the core functionality of the 'RSelenium' or 'seleniumPipes' R pacakges but with a Java-free footprint. The (twisted) 'QT' reactor is used to make the sever fully asynchronous allowing to take advantage of 'webkit' concurrency via QT main loop. Some of Splash features include the ability to process multiple webpages in parallel; retrieving HTML results and/or take screenshots; disabling images or use Adblock Plus rules to make rendering faster; executing custom JavaScript in page context; getting detailed rendering info in HAR format.
The following functions are implemented:
render_html: Return the HTML of the javascript-rendered page.render_har: Return information about Splash interaction with a website in HAR format.render_jpeg: Return a image (in JPEG format) of the javascript-rendered page.render_png: Return a image (in PNG format) of the javascript-rendered page.splash: Configure parameters for connecting to a Splash server
Installation
devtools::install_github("hrbrmstr/splashr")
options(width=120)
Usage
library(splashr)
library(magick)
library(rvest)
library(anytime)
library(hrbrmisc) # github
library(tidyverse)
# current verison
packageVersion("splashr")
## [1] '0.1.0'
splash("splash", 8050L) %>%
splash_active()
## Status of splash instance on [http://splash:8050]: ok. Max RSS: 313761792
splash("splash", 8050L) %>%
splash_debug()
## List of 7
## $ active : list()
## $ argcache: int 0
## $ fds : int 18
## $ leaks :List of 4
## ..$ Deferred : int 50
## ..$ LuaRuntime: int 1
## ..$ QTimer : int 1
## ..$ Request : int 1
## $ maxrss : int 306408
## $ qsize : int 0
## $ url : chr "http://splash:8050"
## - attr(*, "class")= chr [1:2] "splash_debug" "list"
## NULL
Notice the difference between a rendered HTML scrape and a non-rendered one:
splash("splash", 8050L) %>%
render_html("http://marvel.com/universe/Captain_America_(Steve_Rogers)")
## {xml_document}
## <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en" dir="ltr">
## [1] <head>\n<script type="text/javascript" async="async" src="http://uncanny.marvel.com/id?callback=s_c_il%5B1%5D._se ...
## [2] <body>\n<iframe src="http://tpc.googlesyndication.com/safeframe/1-0-5/html/container.html" style="visibility: hid ...
read_html("http://marvel.com/universe/Captain_America_(Steve_Rogers)")
## {xml_document}
## <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en" dir="ltr">
## [1] <head>\n<meta http-equiv="X-UA-Compatible" content="IE=Edge">\n<link href="https://plus.google.com/10852333737344 ...
## [2] <body id="index-index" class="index-index" onload="findLinks('myLink');">\n\n\t<div id="page_frame" style="overfl ...
You can also profile pages:
splash("splash", 8050L) %>%
render_har("http://www.poynter.org/") -> har
data_frame(
start=anytime::anytime(har$log$entries$startedDateTime),
end=(start + lubridate::milliseconds(har$log$entries$time)),
rsrc=sprintf("%02d: %s...", 1:length(start), substr(har$log$entries$request$url, 1, 30))) %>%
mutate(rsrc=factor(rsrc, levels=rev(rsrc))) %>%
bind_cols(xml2::url_parse(har$log$entries$request$url) %>% select(server)) -> df
total_time <- diff(range(c(df$start, df$end)))
total_time <- sprintf("Total time: %s %s",
format(unclass(total_time), digits = getOption("digits")),
attr(total_time, "units"))
ggplot(df) +
geom_segment(data=df, aes(x=start, xend=end, y=rsrc, yend=rsrc, color=server),
size=0.25) +
scale_x_datetime(expand=c(0,0)) +
labs(x=total_time, y=NULL,
title=sprintf("HAR Waterfalll Profile for [%s]", "http://www.poynter.org/")) +
theme_hrbrmstr_msc(grid="") +
theme(legend.position="none") +
theme(panel.background=element_rect(color="#2b2b2b", fill="#2b2b2b"))

And, web page snapshots are easy-peasy too:
splash("splash", 8050L) %>%
render_png("http://marvel.com/universe/Captain_America_(Steve_Rogers)")
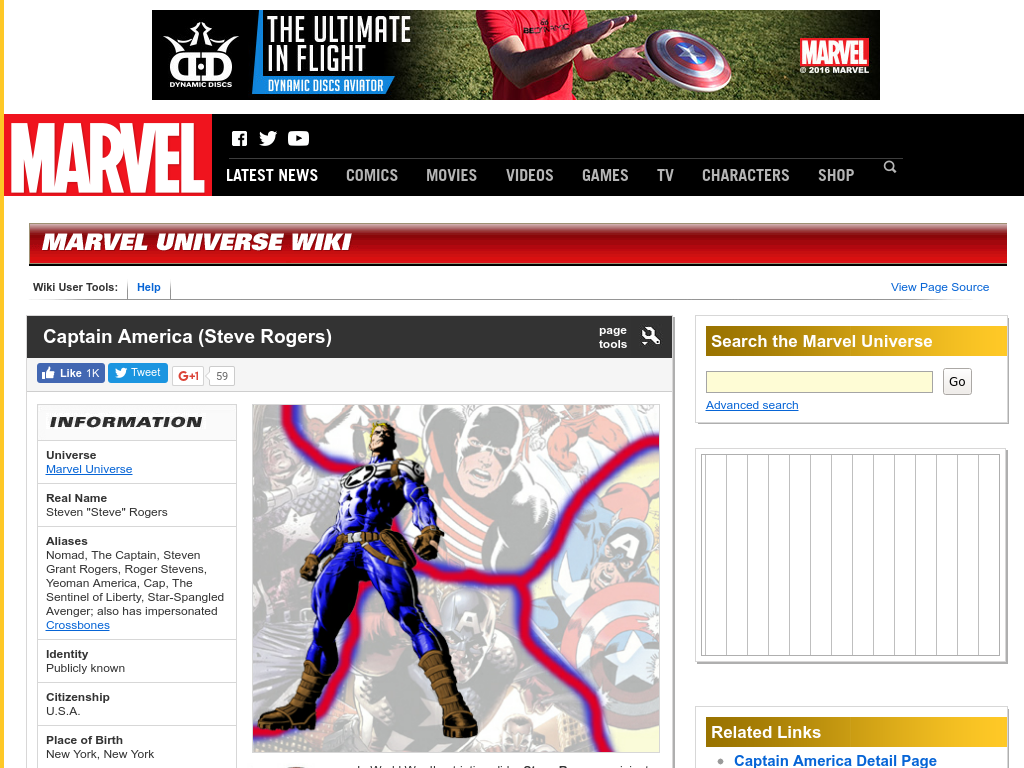
splash("splash", 8050L) %>%
render_jpeg("http://marvel.com/universe/Captain_America_(Steve_Rogers)")

Test Results
library(splashr)
library(testthat)
date()
## [1] "Sat Feb 4 07:01:02 2017"
test_dir("tests/")
## testthat results ========================================================================================================
## OK: 0 SKIPPED: 0 FAILED: 0
##
## DONE ===================================================================================================================